AI技術人材育成講座(1日目)開催レポート
AI技術人材育成講座
さわってわかるAI講座~基礎理論からクラウドサービスを使った実践まで~

令和4年9月13日、高知大学朝倉キャンパスにて、AIに初めて触れる人がAIを活用できるようになるために必要な知識や、最低限必要となる技術を習得する「さわってわかるAI講座」がスタートし、高知大学生11名、一般の方8名が参加しました。4日間の集中講座で、以下の4つのカリキュラムに分かれて実施します。今回は1日目のレポートを公開します。
カリキュラム
■データ活用リテラシー前編(1日目)
- AI/機械学習の概要
- AIの主な種別
- 主要なアルゴリズム
- 多変量解析
- 【ハンズオン】寿司店における発注量予測
- 回帰/分類のアプローチ
- レガシーな機械学習とクラウドサービス
■データ活用リテラシー後編(2日目)
- ニューラルネットワークとディープラーニング
- 入力層、中間層(隠れ層)、出力層
- 【ハンズオン】寿司ネタ識別と精度向上
- 【ハンズオン】寿司店で利用できるその他のAI技術
- AIサービスの設計
- AIと倫理
■データ利活用ワークショップ前編(3日目)
- AIを社会実装するうえでの考察ポイント
- 県内の課題の鳥瞰
- 県内の課題の探求
- AI適用事例
- 県内の課題に対するAI適用検討
■データ利活用ワークショップ後編(4日目)
- 3日目の続き
- 発表資料作成/発表
~講座スタート~
本講座では、高知県を中心に店舗を展開する回転寿司チェーンを例に挙げて、講演、グループワーク、知識テストなどを交えながら、AIの活用について学んでいきます。
最初に、日本が提唱する未来社会のコンセプト「Society5.0」についてお話がありました。
■Society5.0とは
サイバー空間(仮想空間)とフィジカル空間(現実空間)を高度に融合させたシステムにより実現されるスマート社会を言います。具体的には、IoTで全ての人とモノが繋がる世界、地域課題、高齢者のニーズに対応できる社会、情報の探索や分析をAIが行う社会(データの蓄積やネットワークの普及が著しい現代はSociety4.0)を言います。
それを踏まえて、小売のデジタル化の事例として現在、肉や野菜がネットで買えるというネットスーパーや、仲介業者を挟まずに生産者から直接商品を購入できるサイト等、今まであったサービスがデジタル化普及にともなって新たに生まれ変わっていることを再認識しました。
■AIに関する基礎知識のお話
AIはビジネスの世界だけでなく、生活の中に溢れています。「正しいAIの知識を身につけて、理解してほしい。」と講師の鈴木氏。「身近なAIは、スマートフォンの検索エンジンにも使われていて、知りたい情報に素早く辿り着けますし、また、オンライン会議のバーチャル背景の人の認識もAIです。家電では、お掃除ロボットや人の動きや体温を検知するエアコン、洗濯物の素材や汚れ具合で洗濯内容をカスタムする洗濯機など、AIのレベルも様々。」というお話がありました。

今後は精度をさらに上げていく機械学習やディーププランニングが最重要と位置付けられています。
■ワーク
Miroというブレインストーミングツールを使って、受講者がそれぞれ寿司店で活用できそうなAIサービスのアイディアとそれを実践するために必要なものを挙げていき、その後グループになって意見交換をしました。


出てきたアイディア
- 魚の名前で注文せずに「白身」や「柔らかい魚」など、食べたい魚の特徴で寿司を提供しくれるサービス → 注文パネル、魚の個別の情報
- 全てのお客様の注文傾向から次に注文する寿司をおすすめしてくれる → 注文パネル
- 再来店を促すメッセージ送信システム → アンケートチャットボット
など、実現の有無は別にして、今日出てきたアイディアを後日の講座内でどれだけ実現可能かを実践していきます。
■AIとデータ
- データには構造化データと非構造化データがある。
- 表形式で表せたり、機械学習が適用できるものを構造化データと呼ぶ。
- データの細かさをサンプルと呼び、カテゴリーや数値を変数と呼ぶ。
- 注文ごと、来店ごと、顧客ごと、店舗ごとなど構造化データの明細度別に集計することも可能。
- 課題解決の実行結果を評価するためには、目的に合わせたデータの取得が重要で、取得したいデータのイメージを曖昧にしないことで、具体的な検討ができるようになる。
以上を踏まえて、寿司店で収集できる、または収集すべきデータはどういったものかを、再度Miroを使ってワークしてもらいました。

~昼休憩~
午後は、実際に数値を入れて機械学習を行う個人ワークです。
■機械学習の主な流れ
- データを機械に与える(画像の分類)
- 学習フェーズ:事前学習データを大量に機械に読み込ませ、機械学習エンジンに覚えさせると、色、表面の形状など予測するための特徴をまとめて学習モデルを作る。
- 予測フェーズ:蓄積されたデータをもとに、予測の確率を出し、判断する。
これが機械学習のイメージです。
機械学習は、予測、生成、強化学習の3つに分けることができますが、主にはデータから求めたい値を予測するものが多いそうです。
具体的には、将棋ロボットや作業用ロボット、自動運転などがあります。行動を何度も繰り返し、結果をフィードバックしてブラッシュアップすることを強化学習と呼びます。
■機械学習の準備
ワークの前に、機械学習をWEB上でおこなえる「Azure Machine Learning」の準備をしました。
- データセットのアップロード
- 作業場所の新規作成
- 実行環境の作成
- パイプラインの作成
- 実行
■機械学習の流れ
モデルが知らないデータを入れることによって、運用に近い形でモデルの評価をしていくことができます。
■回帰分析
変量間の関係性を数式で表し、連続値の未知の変量(定量データ)を予測することを回帰分析と言います。考慮点としては、目的変数と特徴量は人間が設計する必要があること、特に特徴量の設計がとても大事と言えます。
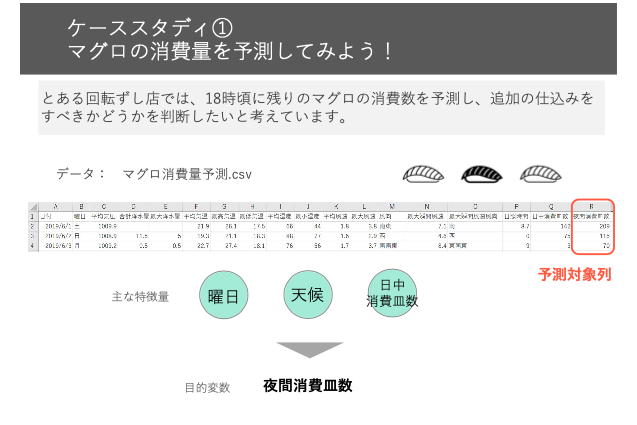
【ケーススタディ】
18時ごろに残りのマグロの消費数を予測して、追加仕込みをすべきかどうか判断したい。
■分類問題
変量間の関係性の把握、未知の変量(定性データ)の値を予測できるというのが分類です。回帰分析と同じで、目的変数と特徴量は人間が設計する必要があります。

初回から様々な意見が飛び交いましたが、皆さんコツコツとワークを進め、個人ワークの際は講師への質問も多く見受けられ、次回に備える様子が伺えました。
